Patrones de diseño - Patrón Observador
Patrón Observer se utiliza cuando hay muchos-uno a la relación entre los objetos como si un objeto es modificado, sus objetos depenedent deben ser notificados automáticamente.Patrón Observer cae bajo la categoría patrón de comportamiento.
Implementación
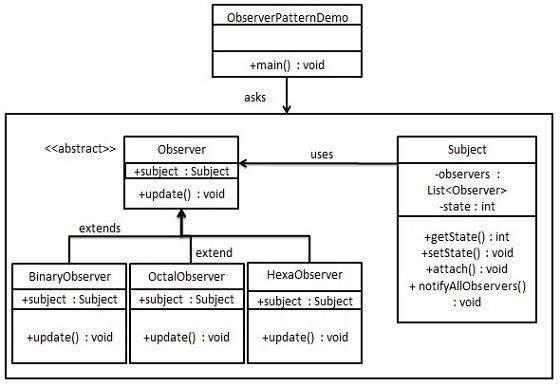
Patrón Observer utiliza tres clases de actores. Asunto, Observador y Cliente. El sujeto es un objeto que tiene métodos para unir y separar los observadores a un objeto cliente. Hemos creado un Observador clase abstracta y una clase de sujeto concreto que se está extendiendo la clase Observer.
ObserverPatternDemo, nuestra clase de demostración, utilizará Asunto y concreto objeto de clase para mostrar el patrón de observador en la acción.
Paso 1
Crear Subject clase.
Subject.java
import java.util.ArrayList;
import java.util.List;
public class Subject {
private List<Observer> observers = new ArrayList<Observer>();
private int state;
public int getState() {
return state;
}
public void setState(int state) {
this.state = state;
notifyAllObservers();
}
public void attach(Observer observer){
observers.add(observer);
}
public void notifyAllObservers(){
for (Observer observer : observers) {
observer.update();
}
}
}
Paso 2
Create Observer class.
Observer.java
public abstract class Observer {
protected Subject subject;
public abstract void update();
}
Paso 3
crar concrete observer classes
BinaryObserver.java
public class BinaryObserver extends Observer{
public BinaryObserver(Subject subject){
this.subject = subject;
this.subject.attach(this);
}
@Override
public void update() {
System.out.println( "Binary String: " + Integer.toBinaryString( subject.getState() ) );
}
}
OctalObserver.java
public class OctalObserver extends Observer{
public OctalObserver(Subject subject){
this.subject = subject;
this.subject.attach(this);
}
@Override
public void update() {
System.out.println( "Octal String: " + Integer.toOctalString( subject.getState() ) );
}
}
HexaObserver.java
public class HexaObserver extends Observer{
public HexaObserver(Subject subject){
this.subject = subject;
this.subject.attach(this);
}
@Override
public void update() {
System.out.println( "Hex String: " + Integer.toHexString( subject.getState() ).toUpperCase() );
}
}
Paso 4
usar objectos observadores Subject y concrete.
ObserverPatternDemo.java
public class ObserverPatternDemo {
public static void main(String[] args) {
Subject subject = new Subject();
new HexaObserver(subject);
new OctalObserver(subject);
new BinaryObserver(subject);
System.out.println("First state change: 15");
subject.setState(15);
System.out.println("Second state change: 10");
subject.setState(10);
}
}
Paso 5
Verificar salida
First state change: 15 Hex String: F Octal String: 17 Binary String: 1111 Second state change: 10 Hex String: A Octal String: 12 Binary String: 1010
Fuente : http://www.tutorialspoint.com/design_pattern/observer_pattern.htm



